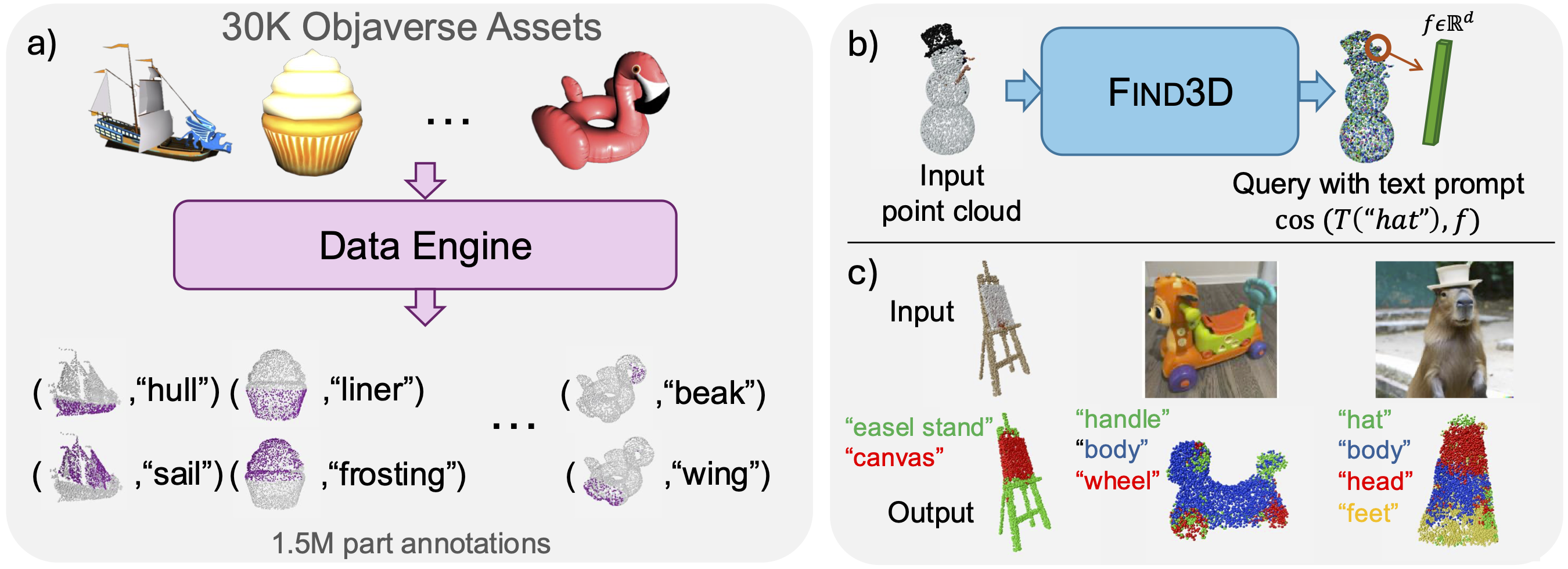
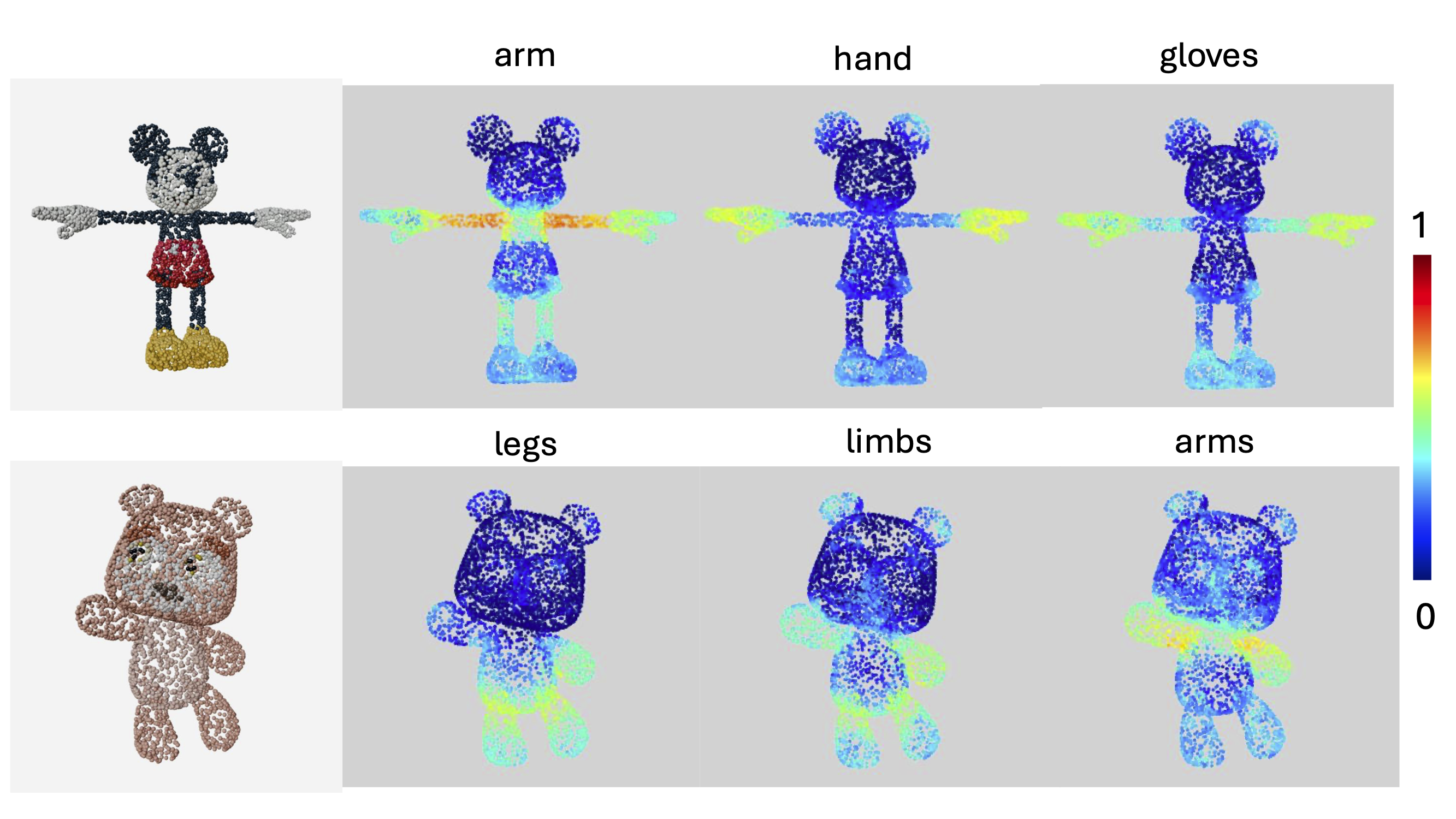
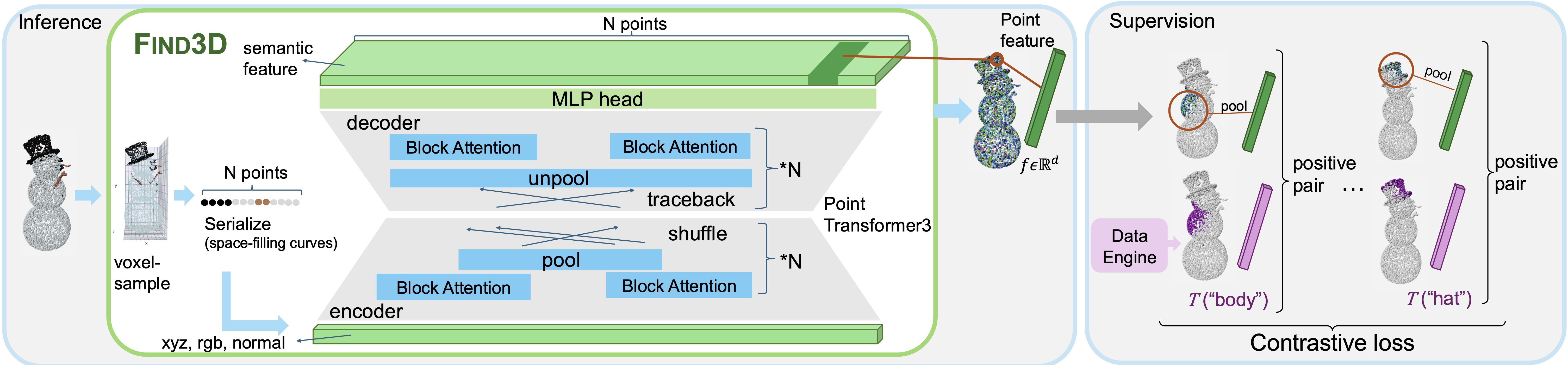
The ability to locate parts in an object is important in embodied applications. However, prior works studying this capability are limited to a small number of object types (such as chairs and tables), and only allow queries for a predefined set of parts. These methods are called "closed-world" segmentation methods. Our method, called Find3D, lifts 3D part segmentation to the open world - you can query any part in any object based on any text query. This is achieved by a powerful data engine which leverages 2D foundation models for creating training data, and a contrastive-based recipe for training a scalable 3D model. Our method allows us to train a model from 2.1 million part annotations and 1755× more unique part times than existing combined! We achieve 260% improvement in mIoU and boost speed by 6× to over 300×. We provide a scaling analysis that underscores the impact of our data engine approach. To encourage research in general-category open-world 3D part segmentation, we also release a benchmark for general objects and parts.